What is data node in Hadoop
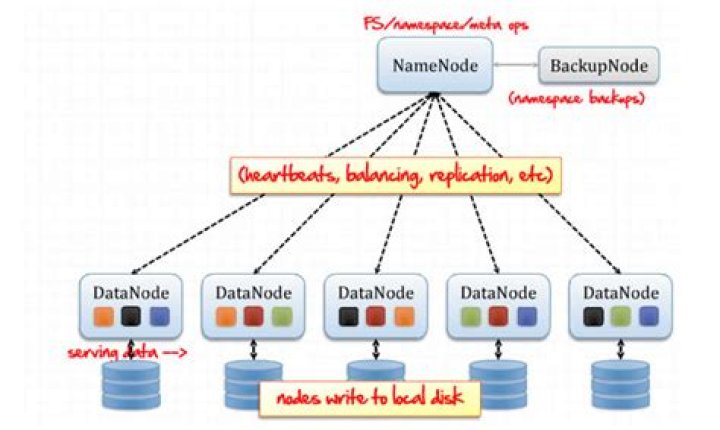
DataNodes are the slave nodes in HDFS. The actual data is stored on DataNodes. A functional filesystem has more than one DataNode, with data replicated across them. … Local and remote client applications can talk directly to a DataNode, once the NameNode has provided the location of the data.
What is a data node?
DataNode is also known as Slave node. 2. In Hadoop HDFS Architecture, DataNode stores actual data in HDFS. … DataNodes sends information to the NameNode about the files and blocks stored in that node and responds to the NameNode for all filesystem operations.
What is main node and data node?
The main difference between NameNode and DataNode in Hadoop is that the NameNode is the master node in HDFS that manages the file system metadata while the DataNode is a slave node in HDFS that stores the actual data as instructed by the NameNode. In brief, NameNode controls and manages a single or multiple data nodes.
What is data node function?
The DataNodes are responsible for serving read and write requests from the file system’s clients. The DataNodes also perform block creation, deletion, and replication upon instruction from the NameNode. The NameNode and DataNode are pieces of software designed to run on commodity machines.What is a big data node?
The computers (seen hereafter as ‘nodes’) that perform the bulk of the computation on the Big Data Cluster are the so-called ‘worker nodes‘. … These 8 nodes, in addition to two other nodes as well as ancillary hardware that facilitates the network, compose the entirety of the Big Data Cluster.
What is NameNode in Hadoop architecture?
NameNode is the master node in the Apache Hadoop HDFS Architecture that maintains and manages the blocks present on the DataNodes (slave nodes). NameNode is a very highly available server that manages the File System Namespace and controls access to files by clients.
What is data node and name node in Hadoop?
The main difference between NameNode and DataNode in Hadoop is that the NameNode is the master node in Hadoop Distributed File System (HDFS) that manages the file system metadata while the DataNode is a slave node in Hadoop distributed file system that stores the actual data as instructed by the NameNode.
What is master node in Hadoop?
Master nodes are responsible for storing data in HDFS and overseeing key operations, such as running parallel computations on the data using MapReduce. The worker nodes comprise most of the virtual machines in a Hadoop cluster, and perform the job of storing the data and running computations.What are name node data node?
NameNode is the master node in the Apache Hadoop HDFS Architecture that maintains and manages the blocks present on the DataNodes (slave nodes). NameNode is a very highly available server that manages the File System Namespace and controls access to files by clients.
What is the difference between TaskTracker and JobTracker?TaskTrackers will be assigned Mapper and Reducer tasks to execute by JobTracker. TaskTracker failure is not considered fatal. When a TaskTracker becomes unresponsive, JobTracker will assign the task executed by the TaskTracker to another node.
Article first time published onWhat is rack awareness in Hadoop?
Rack Awareness in Hadoop is the concept that chooses closer Datanodes based on the rack information. … To improve network traffic while reading/writing HDFS files in large clusters of Hadoop. NameNode chooses data nodes, which are on the same rack or a nearby rock to read/ write requests (client node).
What is namespace in Hadoop?
In Hadoop we refer to a Namespace as a file or directory which is handled by the Name Node. … Namespace act as a container where file name grouping and metadata which also contains things like the owners of files, permission bits, block location, size etc will be present.
How is data stored in Hadoop?
On a Hadoop cluster, the data within HDFS and the MapReduce system are housed on every machine in the cluster. … Data is stored in data blocks on the DataNodes. HDFS replicates those data blocks, usually 128MB in size, and distributes them so they are replicated within multiple nodes across the cluster.
What is namespace and Blockpool?
A Namespace and its block pool together are called Namespace Volume. It is a self-contained unit of management. When a Namenode/namespace is deleted, the corresponding block pool at the Datanodes is deleted. Each namespace volume is upgraded as a unit, during cluster upgrade.
What is the use of pig in Hadoop?
Pig is a high level scripting language that is used with Apache Hadoop. Pig enables data workers to write complex data transformations without knowing Java. Pig’s simple SQL-like scripting language is called Pig Latin, and appeals to developers already familiar with scripting languages and SQL.
What is a cluster and node?
A cluster is a group of servers or nodes. … Every cluster has one master node, which is a unified endpoint within the cluster, and at least two worker nodes. All of these nodes communicate with each other through a shared network to perform operations. In essence, you can consider them to be a single system.
What is Pig and Hive?
Pig is a Procedural Data Flow Language. Hive is a Declarative SQLish Language. 4. It was developed by Yahoo. It was developed by Facebook.
What is heartbeat in HDFS?
A Heartbeat is a signal from Datanode to Namenode to indicate that it is alive. In HDFS, absence of heartbeat indicates that there is some problem and then Namenode, Datanode can not perform any computation.
What is ZooKeeper in big data?
ZooKeeper is an open source Apache project that provides a centralized service for providing configuration information, naming, synchronization and group services over large clusters in distributed systems. The goal is to make these systems easier to manage with improved, more reliable propagation of changes.
Which node stores metadata in Hadoop?
Metadata is the data about the data. Metadata is stored in namenode where it stores data about the data present in datanode like location about the data and their replicas. NameNode stores the Metadata, this consists of fsimage and editlog.
How does name node tackle data node failures?
As soon as the data node is declared dead/non-functional all the data blocks it hosts are transferred to the other data nodes with which the blocks are replicated initially. This is how Namenode handles datanode failures. HDFS works in Master/Slave mode where NameNode act as a Master and DataNodes act as a Slave.
Which protocol is used by name node for communication with data node?
Namenode and datanodes uses RPC to protocol to exchange data between name node and datanodes (HDFS data). All communication between Namenode and Datanode is initiated by the Datanode, and responded to by the Namenode.
What is HDFS and its architecture?
HDFS architecture. The Hadoop Distributed File System (HDFS) is the underlying file system of a Hadoop cluster. It provides scalable, fault-tolerant, rack-aware data storage designed to be deployed on commodity hardware. Several attributes set HDFS apart from other distributed file systems.
Why MapReduce is used in Hadoop?
MapReduce is a Hadoop framework used for writing applications that can process vast amounts of data on large clusters. It can also be called a programming model in which we can process large datasets across computer clusters. This application allows data to be stored in a distributed form.
What is hive and its architecture?
Architecture of Hive Hive is a data warehouse infrastructure software that can create interaction between user and HDFS. The user interfaces that Hive supports are Hive Web UI, Hive command line, and Hive HD Insight (In Windows server). Meta Store.
What is the difference between single node and multi node?
As the name says, Single Node Hadoop Cluster has only a single machine whereas a Multi-Node Hadoop Cluster will have more than one machine. In a single node hadoop cluster, all the daemons i.e. DataNode, NameNode, TaskTracker and JobTracker run on the same machine/host.
What is a single node?
A Single Node cluster is a cluster consisting of an Apache Spark driver and no Spark workers. … A Standard cluster requires a minimum of one Spark worker to run Spark jobs. Single Node clusters are helpful for: Single-node machine learning workloads that use Spark to load and save data.
What is spark cluster?
Introduction to Spark Cluster. A platform to install Spark is called a cluster. … The one which forms the cluster divide and schedules resources in the host machine. Dividing resources across applications is the main and prime work of cluster managers. Acquires resources by working as an external service on the cluster.
What is JobTracker and TaskTracker in Hadoop?
JobTracker is a master which creates and runs the job. JobTracker which can run on the NameNode allocates the job to tasktrackers. It is tracking resource availability and task life cycle management, tracking its progress, fault tolerance etc. TaskTracker run the tasks and report the status of task to JobTracker.
What is difference between task tracker and yarn manager?
Map reduce uses Job tracker to create and assign a task to task tracker due to data the management of the resource is not impressive resulting as some of the data nodes will keep idle and is of no use, whereas in YARN has a Resource Manager for each cluster, and each data node runs a Node Manager.
What is the role of JobTracker and TaskTracker in MapReduce?
JobTracker receives the requests for MapReduce execution from the client. JobTracker talks to the NameNode to determine the location of the data. JobTracker finds the best TaskTracker nodes to execute tasks based on the data locality (proximity of the data) and the available slots to execute a task on a given node.