Which data retention makes Kafka a durable system
Not only can Kafka handle multiple consumers, but durable message retention means that consumers do not always need to work in real time. Messages are committed to disk, and will be stored with configurable retention rules.
What is Kafka durability?
Apache Kafka is able to handle many terabytes of data without incurring much at all in the way of overhead. Kafka is highly durable. Kafka persists the messages on the disks, which provides intra-cluster replication. This makes for a highly durable messaging system.
What is the purpose of retention period in Kafka cluster?
The Kafka cluster retains all published messages—whether or not they have been consumed—for a configurable period of time. For example if the log retention is set to two days, then for the two days after a message is published it is available for consumption, after which it will be discarded to free up space.
What is retention time in Kafka?
A message sent to a Kafka cluster is appended to the end of one of the logs. … If the log retention is set to five days, then the published message is available for consumption five days after it is published. After that time, the message will be de discarded to free up space.What is Kafka tiered storage?
Tiered Storage makes storing huge volumes of data in Kafka manageable by reducing operational burden and cost. The fundamental idea is to separate the concerns of data storage from the concerns of data processing, allowing each to scale independently.
Where does kafka store data?
The default log. dir is /tmp/kafka-logs which you may want to change in case your OS has a /tmp directory cleaner. If no log. dir is defined, then it stores the logs under /tmp/kafka-logs/<topic.name>-<topic.
How do you check the retention of a kafka topic?
If you want to view the configurations for all topic Either you can view these properties log. retention. hours or log.retention.ms in server. properties in kafka config directory.
What is log compaction in Kafka?
Kafka documentation says: Log compaction is a mechanism to give finer-grained per-record retention, rather than the coarser-grained time-based retention. The idea is to selectively remove records where we have a more recent update with the same primary key.What is retention bytes in Kafka topic?
retention. bytes is a size-based retention policy for logs, i.e the allowed size of the topic. Segments are pruned from the log as long as the remaining segments don’t drop below log.
How does tiered storage work?Tiered storage allows companies to store each class of data based on the minimum performance that it requires and the lowest cost storage that can handle those requirements. This in turn eliminates the problem of paying for unneeded high performance storage.
Article first time published onWhat is Kafka architecture?
Kafka is essentially a commit log with a simplistic data structure. The Kafka Producer API, Consumer API, Streams API, and Connect API can be used to manage the platform, and the Kafka cluster architecture is made up of Brokers, Consumers, Producers, and ZooKeeper.
How does Kafka internally work?
A fundamental explanation of Kafka’s inner workings goes as follows: Every topic is associated with one or more partitions, which are spread over one or more brokers. Every partition gets replicated to those one or more brokers depending on the replication factor that is set.
How do I set Kafka retention?
- log. retention. hours.
- log. retention. minutes.
- log.retention.ms.
Are Kafka topics persistent?
As we described, Kafka stores a persistent log which can be re-read and kept indefinitely. Kafka is built as a modern distributed system: it’s runs as a cluster, can expand or contract elastically, and replicates data internally for fault-tolerance and high-availability.
What is offset in Kafka?
OFFSET IN KAFKA. The offset is a unique id assigned to the partitions, which contains messages. … In other words, it is a position within a partition for the next message to be sent to a consumer. A simple integer number which is actually used by Kafka to maintain the current position of a consumer.
How does Kafka store data?
Kafka stores all the messages with the same key into a single partition. Each new message in the partition gets an Id which is one more than the previous Id number. … So, the first message is at ‘offset’ 0, the second message is at offset 1 and so on. These offset Id’s are always incremented from the previous value.
What database does Kafka use?
ksqlDB: An event streaming database for Apache Kafka that enables you to build event streaming applications leveraging your familiarity with relational databases.
Does Kafka store data memory?
Kafka relies on the filesystem for the storage and caching. … Modern operating systems allocate most of their free memory to disk-caching. So, if you are reading in an ordered fashion, the OS can always read-ahead and store data in a cache on each disk read.
How long the data is retained in Kafka?
The Kafka cluster retains all published messages—whether or not they have been consumed—for a configurable period of time. For example if the log retention is set to two days, then for the two days after a message is published it is available for consumption, after which it will be discarded to free up space.
What is segment bytes in Kafka?
segment. bytes is set to the default, it will take 10 days to fill one segment. As messages cannot be expired until the log segment is closed, if log.retention.ms is set to 1 week, they will actually be up to 17 days of messages retained until the closed segment expires.
What is snapshot file in Kafka?
Terminology. Kafka Controller: The component that generates snapshots, reads snapshots and reads logs for voter replicas of the topic partition __cluster_metadata . … This is needed to reply to Metadata RPCs, for connection information to all of the brokers, etc.
How do I enable compression on Kafka?
Approach 2: Set the property compression. type = gzip in Kafka Producer Client API. I get better compression and higher throughput when using Approach 1.
What is log segment in Kafka?
LogSegment is a segment of records of a log of a partition. Tip. Use DumpLogSegments tool to review the content of (the underlying files of) a log segment. LogSegment is composed of two main file types, e.g. the log file itself (with records) and index files.
What is a tiered data?
A tiered data plan is a data service, usually for Internet access for home and mobile data users, in which the user is charged for a differential or variable rate based on the amount of data he or she transmits. It is most common for mobile phone data, but some ISPs also incorporate tiered plans for home Internet use.
What is tiering of data?
Data tiering allows the movement of data between different storage tiers, which allows an organization to ensure that the appropriate data resides on the appropriate storage technology.
What is data tiering in storage?
Data Tiering refers to a technique of moving less frequently used data, also known as cold data, to cheaper levels of storage or tiers. Data Tiering Cuts Costs Because 70%+ of Data is Cold. Data Tiering Was Initially Used within a Storage Array. Flash or SSD: A high-performance storage class but also very expensive.
How does Kafka partition data?
Kafka Partitioning Partitioning takes the single topic log and breaks it into multiple logs, each of which can live on a separate node in the Kafka cluster. This way, the work of storing messages, writing new messages, and processing existing messages can be split among many nodes in the cluster.
How Kafka works in Microservices?
A Kafka-centric microservice architecture refers to an application setup where microservices communicate with each other using Kafka as an intermediary. This is made possible with Kafka’s publish-subscribe model for handling the writing and reading of records.
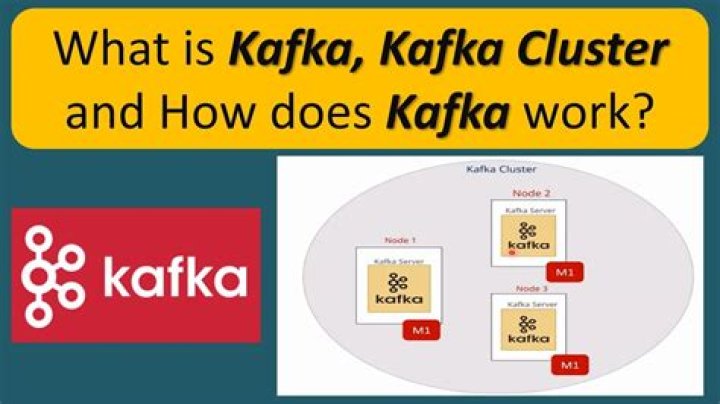
Which Kafka component is used to nourish the Kafka cluster?
The following table describes each of the components shown in the above diagram. Kafka cluster typically consists of multiple brokers to maintain load balance. Kafka brokers are stateless, so they use ZooKeeper for maintaining their cluster state.
Do we always need zookeeper for running Kafka?
Yes, Zookeeper is must by design for Kafka. Because Zookeeper has the responsibility a kind of managing Kafka cluster. It has list of all Kafka brokers with it. It notifies Kafka, if any broker goes down, or partition goes down or new broker is up or partition is up.
What is stream processing in Kafka?
A stream processing application is any program that makes use of the Kafka Streams library. It defines its computational logic through one or more processor topologies, where a processor topology is a graph of stream processors (nodes) that are connected by streams (edges).